Lessons from Six Years in AWS Support: Troubleshooting and Operational Thinking
TL;DR
I spent six years at Amazon Web Services (AWS) as a Cloud Support Engineer, advancing from an associate role to a subject matter expert in container services while supporting enterprise customers globally. This journey taught me deep technical skills in Linux, networking, and containers, along with effective troubleshooting methodologies that prioritized customer impact and quick resolutions. Key takeaways from Amazon include the value of escalating issues promptly, documenting work thoroughly, and building cross-functional networks to deliver exceptional support.
This post reflects my personal experiences and perspectives during my time at AWS. It is not intended as an evaluation of AWS products or a comparison between AWS Support and other organizations.
Introduction
My 6 years at AWS were an interesting and challenging time in my life, full of memories. I reflect on these years as a period of growth and challenge. I want to take this chance to record and summarizes my career progression, key learning. focusing on technical skills, troubleshooting approaches, and Amazon’s operational culture, and review my career here.
Journey in AWS
- 2019: I joined the Taiwan AWS Support team as a Cloud Support Associate(CSA) in September 2019 after graduating from college
- 2020: I passed the internal process to become a Cloud Support Engineer(CSE) in July 2020, starting to assist enterprise-level customers
- 2021: I was relocated to Dublin, Ireland team in March 2021 to support the customer in night shift for the UTC+8 timezone.
- 2022: I was certified by product experts and the development team, becoming a Elastic Container Service(ECS) subject master expert (SME) in August, and promoted to CSE II (L5) in December 2022.
- 2023: I passed the AWS Solutions Architect - Professional certification in Sep 2023.
- 2025: After my 6-year mark and before my 31st years old birthday, I left AWS in September 2025.
Short Story before Joining AWS
Beginning of My Linux Journey
Like many general and normal students, I didn’t know what I want to do when I was still in college. I was in a CSIE department which is famous for software engineering, but I was not keen for coding. And I never learn any IT or information technology knowledge before entering college. However, I decided to find something that I might enjoy and I found out that I like to work with Linux system as I thought working on command line was very cool. I installed Ubuntu 13 on my laptop (I still needed help from my classmate at that time), and studied vbird Linux which is a very famous Linux material for beginner in Taiwan. But somehow I never had a chance to work as system admin.
Internship
In my junior year 2018, I had a chance to work as a Python developer intern in a software company called Larvata, referred by one of my senior classmate in my department. The interesting thing is that the mentor I had is the team lead for DevOps team. During my internship there, I had a chance to see them working on automation, monitoring, and containers, adopting Kubernetes into their environment. The mentor was also keen to share his workflow, on command line and in Vim. In my mind I felt that that’s so cool. I gained valuable experience there.
Interview Loops for AWS Support
In my last year in college, I still don’t know what to do but I ran into the AWS support booth in college career fair. During the conversation the manager and engineer just asked if I want to do an interview in the afternoon on the same day. I was nervous as I wan’t expecting an interview. Nevertheless the questions were related to what I felt interesting, like Linux OS booting process, what happened behind the scene of a browser etc. I was fortune enough to pass the first round but failed the second one. Since then I applied for many different job but I still target AWS support as my job. Even though I was rejected for many jobs, I was also lucky to have few offers as software developer or system admin-related roles, but in the end I rejected all of them and tried to apply for AWS Support again, and then passed the interview that same year.
What I’ve Learned in AWS
Technologies
AWS has incredible and tremendous resources that I couldn’t imagine. From virtualization, operating systems, computer networking L1 to L7, container, CICD pipeline, CDN, database, data analytics, AI/ML etc. And we are encouraged to learn different skills if our capacity and ability allowed (and time!). With a few clicks, I could start an EC2 instance, EKS cluster or ELB to do my lab and troubleshoot. And I had a chance to reach out to the experts with solid skill, knowledge, and experience in different domains; they have different backgrounds like senior system admins, network admins, database admins, software developers, network developers etc. I always wondered why I could be here to work with them.
EC2-Linux
I started from EC2-Linux, get to know more about Linux, and how the underlying hardware and virtualization work. I had amazing mentors and tenured colleagues to teach me. In every knowledge-sharing session, I learned so much from them, from OS troubleshooting like CPU/memory/network/disk performance monitoring and troubleshooting, package manager, to EC2 problems from underlying hardware, SSH connection issue, to network performance like latency under difference conditions like PPS, bandwidth, connection tracking, underlying network components, noisy neighbor etc. Those senior and tenured engineers would dive deep to a level that I couldn’t imagine.
Networking
From time to time we need to support different domains, so I then started to cross-skill to networking services like load balancing and DNS etc. Our tenured engineers provided very solid training from TCP/IP to HTTP, from first-hand materials like RFCs and hands-on labs on basic Linux network socket concept to testing different TCP congestion control algorithms to different HTTP versions. Then I started taking cases like ELB, Route53 etc. Even though I couldn’t handle it well in the beginning but I was very lucky that some engineers still made time for me from their very busy daily schedule to help me. I started to able to help some emergency escalations for networking cases. I remembered during one holiday session that an urgent network case was escalated, but no other tenured network engineer was on that day, and I need to step up to support it. Even though I wasn’t able to find the root cause, I was able to do initial troubleshooting and escalate to the internal team, until we had other senior support engineers step in and start investigating this issue.
Container
As more and more customers adopt containerization in their application and environments, I started to onboard to container services. The training sessions was bottom-up training, from Linux cgroups, namespaces, container networking, the concept of shim, runc to Docker, Amazon ECS, Kubernetes and Amzon EKS. The container services in AWS integrated with other services like EC2, Auto scaling, EBS, EFS, ELB etc. The knowledge I gained before onboarding to container services helped me so much. I was able to gain ECS SME and transfer to deployment (container + CI/CD) profile in the end.
The chance to learn these technical skills was there in AWS but it took time and effort, being willing to take the cases that was initially out of my support skill domains, but the tenured and senior engineers would see the effort and try, and they were willing to help in such cases. I remembered I was once suggested not to join a sharing session as it may be out of my current domain and not helpful for me at that time. So I spent more time and tried to build up my knowledge so I would be qualified to join the sharing session in different domains.
Troubleshooting Skills
Troubleshooting skills are very unique here in AWS from my perspective. Normally, a production accident in a company may happen once or twice probably quarterly or annually. However, troubleshooting an urgent production issue is a day-to-day routine for an AWS support.
SOAP Methodology
In AWS Support, I learned the troubleshooting methodology from healthcare “SOAP”, which is Subjective, Objective, Assessment and Plan. When we troubleshoot a case, it is like a doctor treating a patient; we need to confirm the subjective from the customer’s point of view (pain, impact, time, resource, etc.) and the objective like data, logs, screenshots. A common mistake is to distinguish between the symptoms and signs. Symptoms are the customer’s subjective description, and a sign is an objective finding related to the associated symptom reported by the customer. Then, based on the information we have (the subjective and the objective), we will start the assessment (troubleshooting) and the plan (the next step)
Support can be compared to doctors; some are in the emergency room, who can perform the initial and quick investigation, remediation or workaround, and then determine the next step. Some are specialists, who can have specific knowledge and tools to dive deep for the root causes.
Narrow Down Problems
We need to learn how to collect useful information from the customers and perform valid investigation in a short period, determining the scope of potential root cause or the troubleshooting direction. I remember a tenured engineer once told me that:
A good support engineer will use one question to remove 50% of the potential root causes.
We need to narrow down the potential causes: is it from AWS or the customer’s side? Is it an infrastructure problem or application problem? Is it a networking or OS or container question?
From my experience, for many times the customers open cases and questioned if it was an AWS issue, but in the end it turned out to be something changed in their environment where the customers had the ability to investigate by themselves. I remember a great quote from DevOps Troubleshooting:
One thing I’ve learned in my years as a systems administrator is that when there’s a problem, everyone blames the technology they understand least.
Naturally, people will blame the technology they know least. Even when I do troubleshooting, I would also suspect if something I missed in the domain that I was not familiar with. But many times, if I calmed down and slow down, I would realize that it was actually something within my scope. One of my colleagues told me that when others are in rush, we need to calm down to do our job.
Collecting Information
On many occasions, the customers would not know how to narrow down the issue nor collect the required information when they opened cases during an emergent issue. Some required information would be the issue time(with timezone!), resource IDs, the error messages, the performance metrics from both normal and non-normal times (this is crucial as the quote from Systems Performance:
Performance, on the other hand, is often subjective. With performance issues, it can be unclear whether there is an issue to begin with, and if so, when it has been fixed. What may be considered “bad” performance for one user, and therefore an issue, may be considered “good” performance for another
We also need to understand the background of an incident, like what configuration was changed before, was there any deployment, if there is any test or beta environment we can compare. What’s the real question behind this case: need a solution, need to write a report, or something else? What’s the simplest way to reproduce the same in my test environment?
Source of Truth
I was also educated to be mindful of what source or reference I am refer to during troubleshooting. Is the source an industry spec? Is it an official document? If it is a third-party source, can I trust it? Can I check the source code? If the document says different, can I verify it? Does the log provide the right information? Should I enable debug logs or trace logs to see if there is any more insight?
I had seen it many times that my amazing colleagues explaining to the customer with RFC spec, with open source code. Many times, if the documents had wrong statement, they had detailed lab steps and result to communicate with internal time to correct it.
Checklist
Sometimes it is good to have a checklist when investigating an issue. Netflix performance team has a Linux Performance Analysis in 60,000 Milliseconds to quickly check what happened in a Linux machine. When troubleshooting an EC2, I had a list to check the CloudWatch metrics for EC2 and EBS, the underlying components, the networking components, the monitoring tools I can use.
But I also need to be mindful that a checklist is a good way to quickly check but need to be constantly updated. It is easy to go through the check list without remember the meaning behind these checklist items.
Industries Needs
We would have urgent cases from a vast variety and broad customers, from Fortune 500, new startups, banking, gaming, IoT, crypto, e-commence, social media companies, etc. During troubleshooting and communication, I need to be mindful of the special industry needs. For example, for gaming customer, I need to make sure there are no other workarounds before asking them to restart their EC2 instances, as restart a machine is a high cost to gaming customers. When IoT customer care about static IPs and get upset about IP changes, I need to understand that they could have thousands or millions machines that need be updated. When working with a crypto companies, I can’t be slow; the pace is very fast in crypto market (so is the crypto price).
Working as an AWS support gave me a chance to get to know different industries that I normally wouldn’t have access to.
Case Handling
AWS is excellent at standardize everything. I learned a lot about how to manage a case from the technical, process and big-picture perspective. When I was a new hire, a tenured engineer would review my case from the very beginning to the end to see if I followed the best practice to handle a ticket and give me feedback about how to improve. It really took time for them to review and train me to follow the best practice, which include writing the work log, communication, and follow the process.
I will need to decide the next step, like if I should reproduce the issue first or I should escalate to internal team, when I should seek help from senior engineers, communicate with TAM or engage the ops manager or reply the customer first.
Work Log
Work log is a very important part when working as a support engineer. I need to write down all the information when I handle a case, including the case summary, customer’s pain, troubleshooting steps, reproduction step, external communication with the customer and internal communication. Every agreement with TAM/customer/SDE needs to be recorded. A rule of thumb is that I need to think I am not the only one who will check this ticket. If a case is escalated when I am not on shift and an engineer needs to take over the case or the manager needs to review the case, they can continue everything based on my work log, without reaching out to me for any additional information.
I remember one time when I was on call, a case outside of my technical scope was escalated while the case owner was already off shift. I was able to draft an escalation ticket for that case to our internal team by just following the work log written by the case owner, and our internal team and manager were reproduce the same by the steps in that work log.
A good work log can save a lot of communication and time cost.
Communication
When we support the customer, we may do so by email, online chat or phone call. Every communication is a big part of earning the customer’s trust. I was educated that don’t send any invalid correspondence to the customer, always think what may be the customer’s next question when they read my correspondence, how I can providing an explanation, a workaround, a remediation steps, etc.
Chats and calls are also a big part of AWS Support. When the customers are in production pain, how we can lead the investigation without being affected by the emergency, which is really difficult and challenging, to be honest. I need to stay professional and also show my empathy and acknowledge their feelings. I was educated to calm down and focus on the important things to help the customer. Sometimes when the customers are in pain, they try to ask every question they can think of, but I would need to focus on the real question and pain, keeping the troubleshooting scope small.
A lot of times I may dive deep for troubleshooting, internal escalation. However, if I don’t keep the customer updated, they wouldn’t know what I was doing. The work before the root cause is identified may be in vain if the customers don’t know it.
Escalation
Escalation is a core value in Amazon culture and also AWS Support. If something is out of my control, it will need to be escalated. Velocity is key to solving problems. It seems to contradict some principles we value in Amazon, like dive deep and “learn and be curious.” I have learned and am still learning how to make decisions based on the situation: should I dive deep and troubleshoot, or escalate to a senior engineer, SDE, or TAM to communicate with the customer or managers for some decision-making.
Of course, I should have done my due diligence before escalating to someone and prepare the problem. Practicing providing the proper problem description and ask is also a key skill: what’s the ask, what’s the background, what is known and what is unknown, what steps I have done.
Timing to escalate is still a topic to learn.
Working in Amazon
Team Work
Everyone is busy at Amazon. It is a big company, big team. Everyone has their own role and responsibility. So we should not fight alone when facing a problem. A quote from a developer advocate I admired a lot in AWS is:
The reality is that although AWS as a whole is a collection of brilliant people, there is no single person who has all the knowledge. What I’ve Learned From 6 Years as a Developer Advocate | Nathan Peck
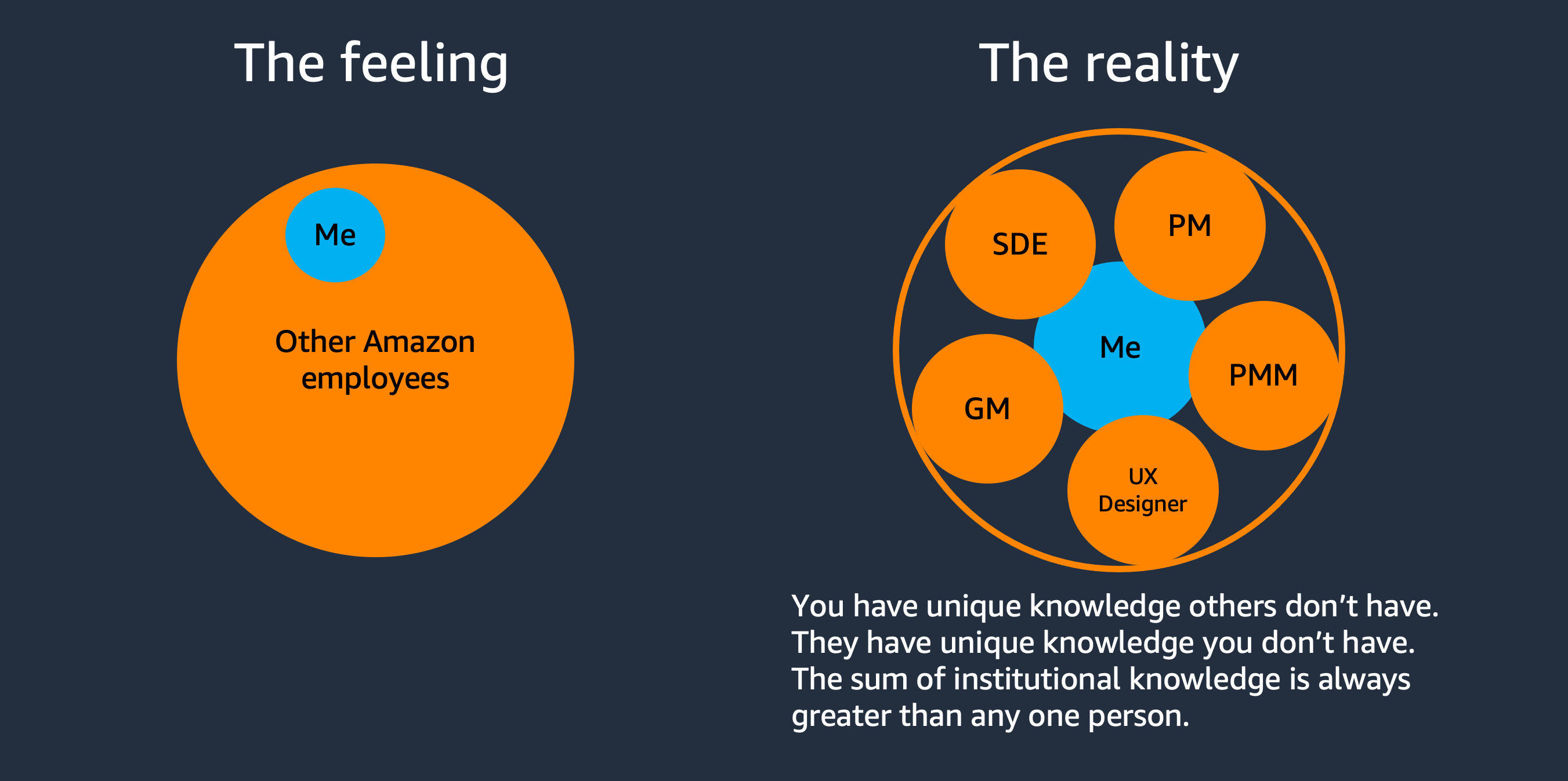
But I also needed to remember that don’t waste others’ time. No one know if they should make time for me if I just say hello when I reach out to someone for help. No Hello is a key when working with the awesome colleagues in Amazon. Try to phrase the right question before reach out and write a STAR format message when reaching out/escalate. So they know how and how long they can help me on my questions. More important, remember to acknowledge others’ effort and give credit by the way I can, shut-out or email or give metrics.
Seize the chance during a team meeting to reach out, to ask questions, to discuss; it is always a great opportunity to learn from the manager, senior engineers, or peers. If there are only announcements and no discussion, it is a lost chance.
Networking
When I left AWS, the people I said goodbye to were peer/senior/principal support engineers, managers within and outside the team, solution architects, TPMs, TAMs from AMER/EMEA/APJC, SDEs. I was so blessed to know all these people and work with and learn from them.
AWS is a place where I can find experts in every technical and non-technical domain.
Operation
The scale in AWS is so large that everyone needs to do things based on data points and metrics. Everyone has their own priorities and how to convince them that mine is more important. To be honest, it is something I was still learning. I was on several projects to improve the engineers’ work environment but unfortunately not able to convince the leadership as it may not be tied to the core metrics of a support team. But I still learned a lot from the process, what I should know and what data I can collect before pushing a project forward.
In AWS, they have many metrics to watch and also processes to improve every metric: CSAT, time to solve the case, the escalation rate, handover, and have a specific process for each metric, based on the data points. I felt like it is a two-edged sword. As what Bezos said, metrics are proxies; if they cannot reflect the true situation and feeling, they are not valid. It is still hard to value a support engineer’s value: by the number of cases resolved, by the technical depth of the case, by the customer management and case handling, by the project impact. An engineer can resolve a case in 15 minutes not because the problem is easy, it is because of the experience this engineer has accumulated.
Every team in AWS needs to prove why they exist, get to know the business model of each team to know how important this organization is in the company. Focus on the things that bring value to the team.
I personally think, from some point, a support team cannot afford to lose a tenured engineer more than a developer team can. In these 6 years, I can see that tenured engineers come and go. However, the customers are the same people. The questions they ask now are very different from what they asked when I started my career in AWS. A tenured support engineer will learn and gain the knowledge and experience together with the customers. A tenured engineer can gain the trust from the customer and account team. However, if a tenured engineer leaves, it is hard to train the same one to face the customers who have known AWS so well.
Amazon Culture
Amazon is well-known for its leadership principles. I agree the leadership principles are very important, but talking about the leadership principles is an art of communication and education. I was fortunate enough when I joined that I could learn from some Amazonians who had the correct and proper understanding and valued the culture and leadership principles. They were keen to share and educate me, like how to make decisions based on these principles in various scenarios.
However, as the team grows, more and more processes/playbooks/runbooks were introduced into the team. When making the processes, there are always exceptional situations; if someone doesn’t have the right understanding of the principles, they may not know what to do. Processes/playbooks/runbooks are also a two-edged sword. The more detailed they are listed, the more exceptions will happen. When following a principle, there might be a chance that we may not make the best decision or even make a mistake, but creating a culture with principles is more resilient.
Writing
Writing in Amazon is famous. We don’t use PowerPoint for internal communication, which I felt amazed at in the beginning. But gradually I got used to it and feel like it is indeed the right way. We can communicate things in a doc, one-page or six-page. When I wanted to search for a proposal, I would instinctively want to find the initiative or the PRFAQ for it. I came to learn that if I want to discuss some proposal with others or leadership, a simple doc is required. It helped me to think when I wrote the doc. It is an interesting experience when everyone sits in a meeting and is silent for 15 minutes to just read the doc and put comments.
In the past, when I tried to propose a plan for improving the engineers’ work environment, I also wrote a one-page document (one-page). During the meeting, the managers and team members would sit down together to read the document I wrote. Everyone would write down comments and annotations on the document: What does this sentence mean? How was the data collected? Why does it support your argument? Is there a better way to examine the expected results? And so on. Then, I would go back to review and revise this document.
I would learn what is missing, what to improve, and how to make a proposal more complete through the process.
The End and Start
Thank you for walking with me through my journey in AWS. The decision of leaving Amazon was difficult and mixed-feelings. Sometimes when handling the cases every day, I felt like I was learning something, but sometimes I was not learning something for my career from some points. I felt like my growth was on track but seemed not at the same time. I am very grateful for what I’ve learned at AWS but I also knew I needed a different environment to explore and gain experience for my career. I am excited and look forward to my next chapter too and to continue to learn with you all.